
人类的语言是一种复杂智力产物,也许正如圣经故事里说的那样,为了不让人类建造出通天的巴别塔来宣扬人类的名,而故意混乱了人类的语言,让人类语言变得无比复杂。人工智能一个核心课题就是自然语言处理,但是由于人类语言的复杂性,各种算法的表现都不够完美。
深度学习现在基本是人工智能领域绕不开的一个词汇,深度学习确实在图像识别,语音识别领域取得了突飞猛进的进展,甚至是革命性的进展。深度学习俨然已经成为了人工智能领域的强大引擎。最近人机博弈领域采用深度学习也取得了围棋方面的进展,现在的算法在不需要人类让子的情况下已经可以击败职业2段选手。
在自然语言领域似乎很难有深度学习施展的空间。有一种说法是:语言(词、句子、篇章等)属于人类认知过程中产生的高层认知抽象实体,而语音和图像属于较为底层的原始输入信号,所以后两者更适合用深度学习来学习特征。但是在2015年自然语言处理领域顶级的学术会议EMNLP上不仅录用了大量的应用深度学习的论文,还特邀了约书亚•本吉奥教授作了特邀报告,而约书亚•本吉奥教授也是复兴深度学习的主要学者之一,这说明深度学习在自然语言领域也获得了巨大关注。在工程实践中我们也小有成就,利用深度学习方式构建的情感判断模型也表现出了较高的准确性。
把深度学习应用于自然语言处理的的第一步就是需要把最小语义单位词转化成深度神经网络可以处理的数值型的数据。也是需要一种用数值来表示词。最常用的词表示方法就是one-hot,把每个词表示为一个很长的向量。这个向量的维度是词典的大小,其中只有一个维度的值为 1,其他维度都为0,这个为1的维度就代表了当前的词。对于汉语来说这个向量的维度为20万左右。例如:
“桌子”表示为 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 …]
“公里”表示为 [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 …]
这种方式等于给每个词分配了一个唯一的数值。这种方式被应用于最大熵、SVM等可以完成文本分类,文本相似度计算等自然语言处理的任务。这个方式有一些问题,首先如果出现了不在词典中的新词,那么每个词的维度都需要增加。另一个重要的问题就是“词汇鸿沟”问题,就算语义相同的两个词他们的one-hot值之间也毫无关系。
为了避免one-hot带来的问题,词嵌入方式被提了出来。词嵌入一般是使用50~200维的向量来表示一个词,例如:
W("公鸡") = (0.31,0.56.....0.42)
W("母鸡") = (0.29,0.62.....0.35)
词嵌入有一个特点就是两个语义相近的词,对应的词嵌入之间的距离(一般是指余玄)距离也比较近。把词表示成立一个向量,那么我们就可以对进行一些向量的计算了,例如:
W("中国")+W("北京") ≃ W("日本")+W("东京")
W("国王")-W("男人") ≃ W("王后")-W("女人")
词嵌入之间的计算说明了词之间一定的语义之间的逻辑关系,也从一个侧面说明了词嵌入可以表达一定的语义。
词嵌入是通过大量语料训练而来。训练词嵌入时会假设存在一个函数R可以判断由多个词嵌入组成的语句是否成立。例如
R(W("吃"),W("葡萄"),W("要"),W("吐"),W("皮"))=1
R(W("吃"),W("葡萄"),W("飞"),W("吐"),W("皮"))=0
上面第1个表达式成立而第2个不成立,训练的过程就是通过一个BP神经网络拟合R函数,而词嵌入就是通过BP神经网络获取的参数。
词嵌入是自然语言通往深度学习的一座桥梁。有了词嵌入我们就可以把语句作为原本用于图片识别的卷积神经网络的输入,而多层的卷积神经网络是一种典型的深度学习模型。下图就是应用来识别手写体的卷积神经网络结构图。
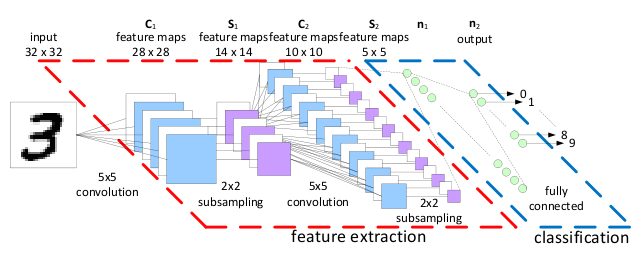
假设一条句子由N个词组成,而每个词都可以转化为D维的词嵌入,那么一个句子就可以被看成一个N*D的矩阵。
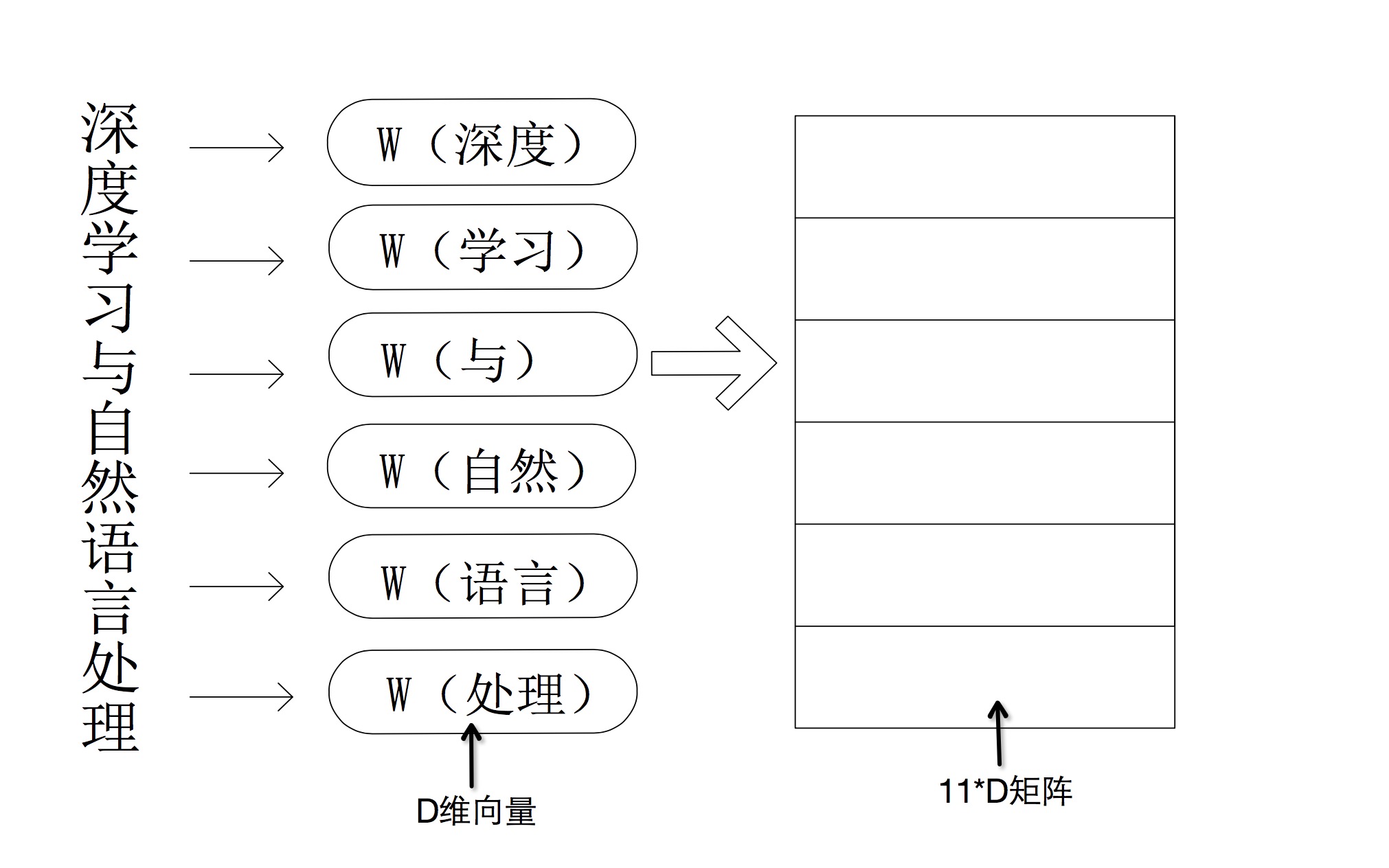
通常卷积神经网络都被用于图片识别或者图片分类,数字化图片的本质也就是一个由像素组成的矩阵,每个像素用三个字节来表示该像素的颜色值。所以卷积神经网络的输入正好就是一个矩阵,如上图右边部分,自然语言的语句可以转化成词嵌入矩阵,而这个矩阵就作为卷积神经网络的输入。也就是说我们使用卷积神经网络的方式对自然语言进行语义方面的处理。